Задача для анализа : руководством торговой сети розничных магазинов одежды было принято решение добавить в ассортимент новую позицию - мужские трусы. По прошествии некоторого времени поставлена задача проанализировать продажи с точки
зрения покупательских предпочтений в разрезах пола, возраста, модели и цвета.
зрения покупательских предпочтений в разрезах пола, возраста, модели и цвета.
Для анализа были подготовлены следующие данные :
df = pd.read_excel("data/undpants_sales.xlsx")
df.head()
df.head()
customer_sex customer_age clothing_sex clothing_cat model color
0 male 59 male Jacket NaN NaN 1 female 39 male Jacket NaN NaN 2 female 40 female Trousers NaN NaN 3 female 46 female Trousers NaN NaN 4 female 65 female Trousers NaN NaN
Данные представляют собой продажи в разрезе : пол и возраст покупателя, пол и товарная группа покупки. Так как цель анализа - мужские трусы, то по ним есть дополнительная информация - модель и цвет.
Обозначения :customer_sex - пол покупателя,customer_age - возраст покупателя,clothing_sex - пол товарной группы покупкиclothing_cat - товарная группа покупкиmodel - модель трусовcolor - цвет трусов
#Типы переменных
df.dtypes
customer_sex object customer_age int64 clothing_sex object clothing_cat object type object color object dtype: object
#Размер данных
df.shape(20127, 6)
Выделим колонки с объектными данными
ob_cols = [c for c in df.columns if df[c].dtypes=='O']
ob_cols
['customer_sex', 'clothing_sex', 'clothing_cat', 'model', 'color']Выведем уникальные значения в этих колонкахfor col in ob_cols: print(len(df[col].unique()),df[col].unique())Добавим в данные новую колонку - индекс покупки мужских трусовdef f(row): return (1 if row['clothing_sex']=='male' and row['clothing_cat']=='Underpants' else 0)df['ind'] = df.apply(f, axis=1)df.head()
Выведем долю продаж трусов в общих продажах :
print('male underwear % : ',round(df.ind.mean(),4))
male underwear % : 0.0589
Посмотрим как покупки мужских трусов распределились по полу покупателяind_sum_by_customer_sex = df.groupby(by='customer_sex')['ind'].sum()ind_sum_by_customer_sex/df.ind.sum()Доли в продажах практически равные
Сгруппируем общие продажи и продажи трусов по возрасту и выведем их распределение
by_age = df.groupby(by='customer_age')['customer_age'].count()
ind_by_age = df.groupby(by='customer_age')['ind'].sum()
ax1 = by_age.plot(grid=True,figsize=(10, 7),title='number of sales')
ax1.set_xlabel('age')
ax1.set_ylabel('all sales',color='b')
ax2 = ax1.twinx()
ax2 = ind_by_age.plot(color='r')
ax2.set_ylabel('Underpants', color='r')

Разделим возраст на интервалы и выведем процент продаж трусов в этих интервалах
df['age_group'] = df['customer_age'].apply(
lambda x: '[15, 30)' if x < 30 else '[30, 40)' if x < 40 \
else '[40, 50)' if x < 50 else '[50, 60)' if x < 60 \
else '[60, 70)' if x < 70 else '70+'
)
Посмотрим, как по возрасту распределилась доля трусов в общих покупках :
У женщин
ind_by_age_group_male = df.query('customer_sex=="female"'). groupby(by='age_group')['ind'].mean() * 100.0
ind_by_age_group_male
age_group 70+ 3.867403 [15, 30) 4.579208 [30, 40) 3.986333 [40, 50) 4.405846 [50, 60) 5.208333 [60, 70) 5.319149 Name: ind, dtype: float64ind_by_age_group_female.plot.bar(title='% of Underpants in total sales (female)')

У мужчин
ind_by_age_group_male = df.query('customer_sex=="male"'). groupby(by='age_group')['ind'].mean() * 100.0ind_by_age_group_male age_group 70+ 10.344828 [15, 30) 8.603239 [30, 40) 8.103263 [40, 50) 6.820084 [50, 60) 8.466604 [60, 70) 12.419700 Name: ind, dtype: float64ind_by_age_group_male.plot.bar(title='% of Underpants in total sales (male)')
Доли возрастных групп в общих продажах и в продажах мужских трусовplt.figure(figsize=(12, 7)) plt.subplot(1, 2, 1) plt.title('all sales') sum_by_age_group.plot( kind='pie', startangle=90, subplots=True, autopct=lambda x: '%0.1f%%' % x ); plt.subplot(1, 2, 2) plt.title('Underpants sales') ind_sum_by_age_group.plot( kind='pie', startangle=90, subplots=True, autopct=lambda x: '%0.1f%%' % x )


Осталось посмотреть, как распределяются продаж в возрастных группах по моделям и по цветам
Пол - возраст - модель
sex_age_model_df = df.groupby(['age_group','customer_sex',
'model'])['ind'].sum().unstack('model').fillna(0)
sex_age_model_df = sex_age_model_df.divide(
df.groupby(
by=['age_group','customer_sex']
)['ind'].sum(),
axis=0
)
ax=sex_age_model_df.plot.bar(stacked=True)
ax.legend(loc='center right', bbox_to_anchor=(1.3, 0.5), ncol=1)
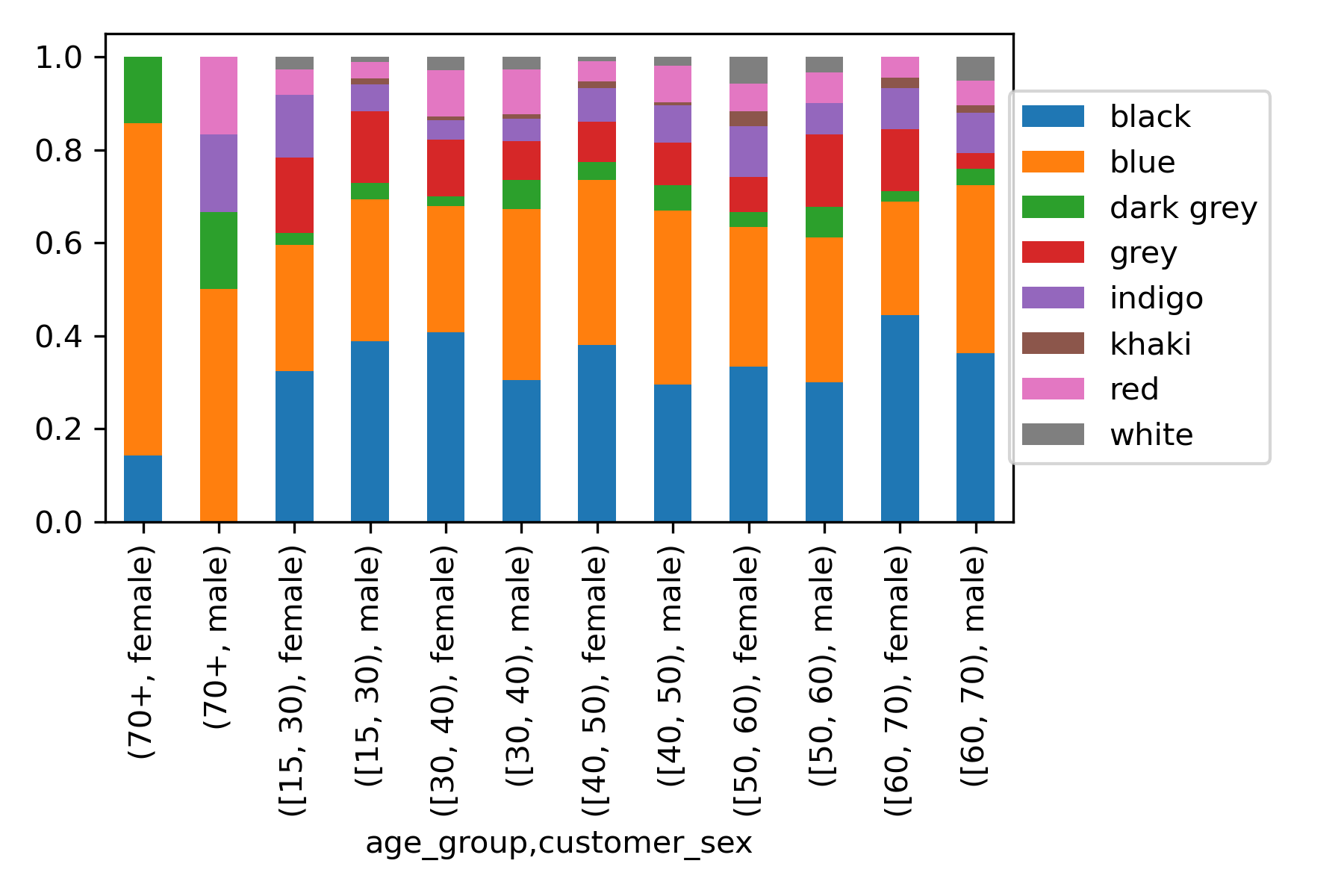
Пол - возраст - цветsex_age_model_df = df.groupby(['age_group','customer_sex', 'color'])['ind'].sum().unstack('color').fillna(0) sex_age_color_df = sex_age_model_df.divide( df.groupby( by=['age_group','customer_sex'] )['ind'].sum(), axis=0 )ax=sex_age_color_df.plot.bar(stacked=True) ax.legend(loc='center right', bbox_to_anchor=(1.3, 0.5), ncol=1)

Комментариев нет:
Отправить комментарий