Продолжаем осваивать автоматизированное машинное обучение с с библиотеками PyCaret и TROT, переходим к классификации и начнем с примера из книги "Tolios G. Simplifying Machine Learning with PyCaret: A Low-code Approach for Beginners and Experts"
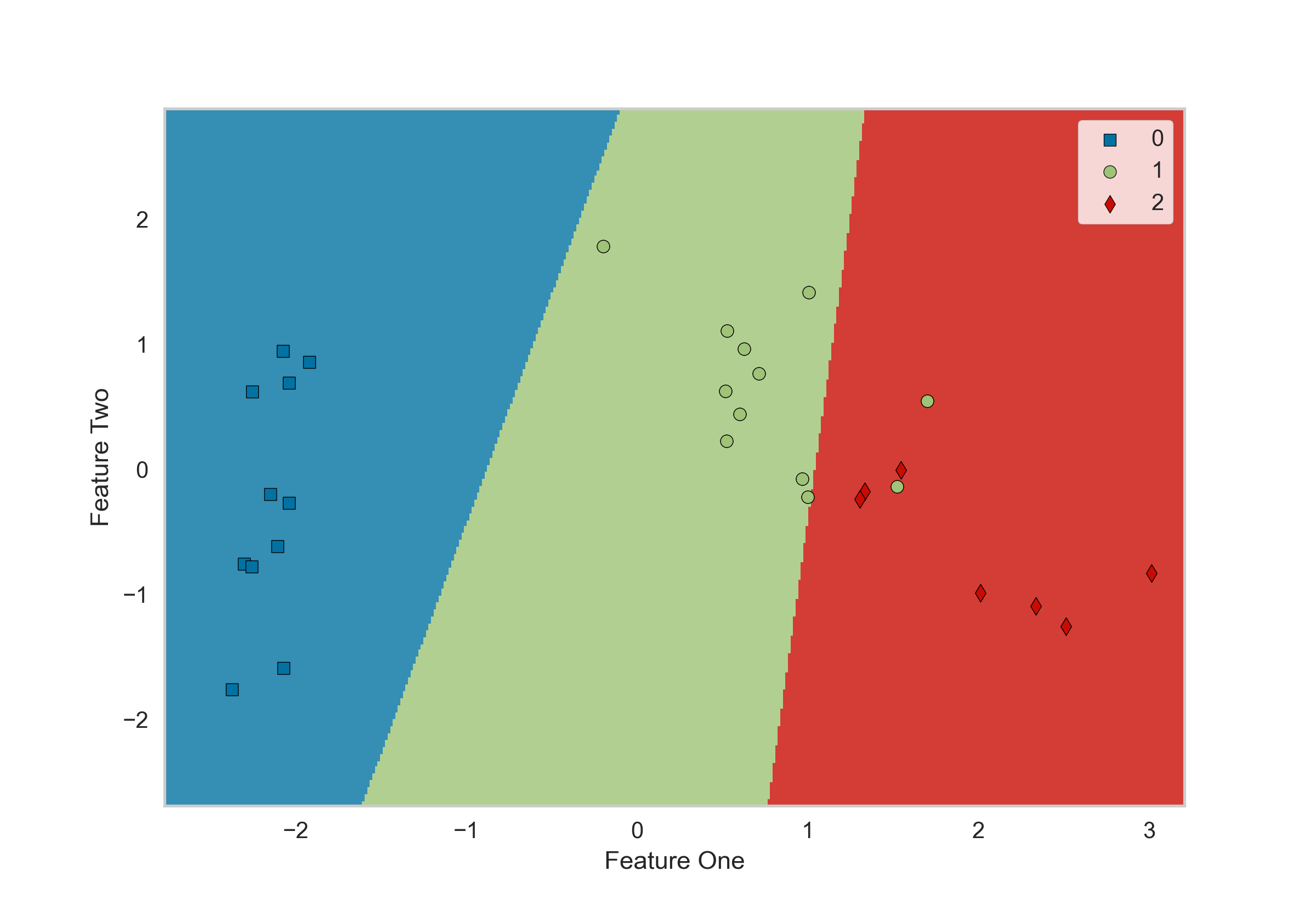
Классификация является одной из основных задач обучения с учителем, целью которой является предсказание категориальной переменную или метки класса. Эта задача известна как бинарная классификация, когда есть только два класса (0 и 1), или многоклассовая классификация если классов больше. Одной из наиболее широко используемых моделей бинарной классификации является логистическая регрессия. Помимо логистической регрессии, существует множество других доступных моделей классификации, таких как дерево решений, K-ближайших соседей, линейный дискриминантный анализ и XGBoost. В этой статье мы разберем, как библиотека PyCaret может помочь в выборе оптимальной модели классификации.
Начнем с импорта необходимых библиотек Python.
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
import seaborn as sns
from pycaret.datasets import get_data
from pycaret.classification import *
mpl.rcParams['figure.dpi'] = 300
| sepal_length | sepal_width | petal_length | petal_width | species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
<class 'pandas.core.frame.DataFrame'> RangeIndex: 150 entries, 0 to 149 Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 sepal_length 150 non-null float64 1 sepal_width 150 non-null float64 2 petal_length 150 non-null float64 3 petal_width 150 non-null float64 4 species 150 non-null object dtypes: float64(4), object(1) memory usage: 6.0+ KB
Далее выполним небольшой исследовательский анализ данных (EDA).
EDA является необходимой частью каждого проекта машинного обучения,поскольку помогает понять основные статистические свойства набора данных спомощью визуализаций.
data['species'].value_counts().plot(kind='pie')
plt.ylabel('')
Функция setup() инициализирует среду в pycaret и создает конвейер преобразования для подготовки данных для моделирования и развертывания. setup() необходимо вызывать
перед выполнением любой другой функции в pycaret. Он принимает два обязательных
параметра: DataFrame pandas и имя целевого столбца. Все остальные параметры
являются необязательными и используются для настройки конвейера предварительной обработки.
Разберем параметры, заданные в примере :
data - типа DataFrame Pandas
Набор данных с формой (n_samples, n_features), где n_samples — количество выборок, а n_features — количество признаков. Если данные не являются DataFrame pandas, они преобразуются в DataFrame с использованием имен столбцов по умолчанию.
target: int, str или последовательность, по умолчанию = -1
Если int или str, соответственно индекс или имя целевого столбца в данных. Значение
по умолчанию выбирает последний столбец в наборе данных. Если
последовательность, она должна иметь форму (n_samples). Цель может быть либо
бинарной, либо мультиклассовой.
train_size: с плавающей запятой, по умолчанию = 0,7
Доля набора данных, которая будет использоваться для обучения и проверки. Должно
быть между 0,0 и 1,0.
session_id: целое, по умолчанию = None
Предоставляет начальное значение внутреннему генератору случайных чисел,
эквивалентно «random_state» в scikit-learn. Если None, генерируется псевдослучайное
число. Используется для последующей воспроизводимости всего эксперимента.
normalize: bool, по умолчанию = False
Если установлено значение True, он преобразует объекты, масштабируя их до
заданного диапазона. Тип масштабирования определяется параметром
normalize_method.
После запуска функции setup() распечатывается таблица с ее параметрами
и настройками.
| Model | Accuracy | AUC | Recall | Prec. | F1 | Kappa | MCC | TT (Sec) | |
|---|---|---|---|---|---|---|---|---|---|
| lda | Linear Discriminant Analysis | 0.9833 | 0.9979 | 0.9833 | 0.9867 | 0.9831 | 0.9750 | 0.9769 | 0.0100 |
| qda | Quadratic Discriminant Analysis | 0.9750 | 1.0000 | 0.9750 | 0.9822 | 0.9738 | 0.9625 | 0.9668 | 0.0110 |
| nb | Naive Bayes | 0.9583 | 0.9915 | 0.9600 | 0.9667 | 0.9578 | 0.9374 | 0.9420 | 0.0120 |
| rf | Random Forest Classifier | 0.9583 | 0.9922 | 0.9600 | 0.9667 | 0.9578 | 0.9374 | 0.9420 | 0.1440 |
| et | Extra Trees Classifier | 0.9583 | 0.9979 | 0.9600 | 0.9667 | 0.9578 | 0.9374 | 0.9420 | 0.1280 |
| xgboost | Extreme Gradient Boosting | 0.9583 | 0.9798 | 0.9600 | 0.9667 | 0.9578 | 0.9374 | 0.9420 | 0.0430 |
| lr | Logistic Regression | 0.9500 | 1.0000 | 0.9517 | 0.9600 | 0.9493 | 0.9249 | 0.9304 | 0.7970 |
| knn | K Neighbors Classifier | 0.9500 | 0.9873 | 0.9517 | 0.9567 | 0.9495 | 0.9245 | 0.9282 | 0.0140 |
| lightgbm | Light Gradient Boosting Machine | 0.9500 | 0.9875 | 0.9517 | 0.9567 | 0.9496 | 0.9249 | 0.9286 | 0.1880 |
| dt | Decision Tree Classifier | 0.9417 | 0.9562 | 0.9433 | 0.9522 | 0.9403 | 0.9124 | 0.9185 | 0.0110 |
| gbc | Gradient Boosting Classifier | 0.9417 | 0.9865 | 0.9433 | 0.9556 | 0.9400 | 0.9124 | 0.9203 | 0.1230 |
| ada | Ada Boost Classifier | 0.9333 | 0.9882 | 0.9350 | 0.9524 | 0.9287 | 0.8999 | 0.9113 | 0.0530 |
| catboost | CatBoost Classifier | 0.9333 | 0.9979 | 0.9350 | 0.9433 | 0.9327 | 0.8999 | 0.9054 | 0.4420 |
| svm | SVM - Linear Kernel | 0.9083 | 0.0000 | 0.9100 | 0.9233 | 0.9060 | 0.8620 | 0.8711 | 0.0100 |
| ridge | Ridge Classifier | 0.8167 | 0.0000 | 0.8111 | 0.8590 | 0.8012 | 0.7228 | 0.7525 | 0.0120 |
| Accuracy | AUC | Recall | Prec. | F1 | Kappa | MCC | |
|---|---|---|---|---|---|---|---|
| 0 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| 1 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| 2 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| 3 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| 4 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| 5 | 0.9167 | 1.0000 | 0.9167 | 0.9333 | 0.9153 | 0.8750 | 0.8843 |
| 6 | 0.9167 | 0.9792 | 0.9167 | 0.9333 | 0.9153 | 0.8750 | 0.8843 |
| 7 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| 8 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| 9 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| Mean | 0.9833 | 0.9979 | 0.9833 | 0.9867 | 0.9831 | 0.9750 | 0.9769 |
| SD | 0.0333 | 0.0063 | 0.0333 | 0.0267 | 0.0339 | 0.0500 | 0.0463 |
| Accuracy | AUC | Recall | Prec. | F1 | Kappa | MCC | |
|---|---|---|---|---|---|---|---|
| 0 | 0.9167 | 0.9792 | 0.9167 | 0.9333 | 0.9153 | 0.8750 | 0.8843 |
| 1 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| 2 | 0.9167 | 1.0000 | 0.9167 | 0.9333 | 0.9153 | 0.8750 | 0.8843 |
| 3 | 0.9167 | 0.9896 | 0.9167 | 0.9333 | 0.9153 | 0.8750 | 0.8843 |
| 4 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| 5 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| 6 | 0.9167 | 0.9792 | 0.9167 | 0.9333 | 0.9153 | 0.8750 | 0.8843 |
| 7 | 0.9167 | 1.0000 | 0.9333 | 0.9333 | 0.9167 | 0.8737 | 0.8830 |
| 8 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| 9 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| Mean | 0.9583 | 0.9948 | 0.9600 | 0.9667 | 0.9578 | 0.9374 | 0.9420 |
| SD | 0.0417 | 0.0084 | 0.0403 | 0.0333 | 0.0422 | 0.0626 | 0.0580 |
| sepal_length | sepal_width | petal_length | petal_width | species | Label | Score | |
|---|---|---|---|---|---|---|---|
| 0 | -0.085637 | 2.256249 | -1.480436 | -1.354654 | Iris-setosa | Iris-setosa | 1.000 |
| 1 | 1.198925 | 0.114993 | 0.883009 | 1.120194 | Iris-virginica | Iris-virginica | 0.999 |
| 2 | -0.319194 | -1.312511 | 0.038922 | -0.182357 | Iris-versicolor | Iris-versicolor | 1.000 |
| 3 | 0.615033 | 0.352911 | 0.826737 | 1.380705 | Iris-virginica | Iris-virginica | 1.000 |
| 4 | -0.435973 | 2.732084 | -1.367891 | -1.354654 | Iris-setosa | Iris-setosa | 1.000 |
| 5 | -1.136643 | -0.122924 | -1.367891 | -1.354654 | Iris-setosa | Iris-setosa | 1.000 |
| 6 | -0.786308 | 1.066663 | -1.311618 | -1.354654 | Iris-setosa | Iris-setosa | 1.000 |
| 7 | -0.903086 | 1.780415 | -1.255346 | -1.354654 | Iris-setosa | Iris-setosa | 1.000 |
| 8 | -0.085637 | -1.074594 | 0.095194 | -0.052102 | Iris-versicolor | Iris-versicolor | 1.000 |
| 9 | -0.903086 | 1.542498 | -1.311618 | -1.094143 | Iris-setosa | Iris-setosa | 1.000 |

Комментариев нет:
Отправить комментарий