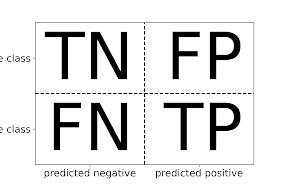
Рассмотрим основные метрики качества в задачах классификации : доля правильных ответов, точность, полнота, F-мера и матрица ошибок. А также четыре различных комбинации фактических и прогнозируемых значений: истинно отрицательные (TN), ложноотрицательные (FN), истинно положительные (TP) и ложноположительные (FP).
Напомним, что в случае бинарной классификации мы говорим о положительном (positive) классе и отрицательном (negative) классе, подразумевая под положительным классом интересующий нас класс.
True Positive (TP) — это общее количество предсказанных положительных результатов, которые на самом деле являются положительными.
True Negative (TN) — это общее количество предсказанных отрицательных результатов, которые на самом деле являются отрицательными.
Ложное срабатывание (FP), ошибка 1 рода, — это общее количество предсказанных положительных результатов, которые на самом деле являются отрицательными.
Ложноотрицательный (FN), ошибка 2 рода — это общее количество предсказанных отрицательных результатов, которые на самом деле являются положительными.
#### Доля правильных ответов (Accuracy Score)
$$Accuracy Score = \frac{Correct Predictions}{All Predictions} = \frac{TP + TN}{TP + TN + FP + FN}$$
#### Точность (Precision)
$$Positive Precision = \frac{True Positive}{Predicted Positive} = \frac{TP}{TP + FP}$$
$$Negative Precision = \frac{True Negative}{Predicted Negative} = \frac{TN}{TN + FN}$$
#### Полнота (Recall)
$$Positive Recall = \frac{True Positive}{Actual Positive} = \frac{TP}{TP + FN}$$
$$Negative Recall = \frac{True Negative}{Actual Negative} = \frac{TN}{TN + FP}$$
$$\frac{2*Precision*Recall}{Precision+Recall}$$
В качестве примера рассмотрим следующую задачу : в период с января по март происходит большая часть увольнений торгового персонала, необходимо создать модель, которая по ряду показателей сотрудника определяла в нем потенциального кандидата на увольнение. В этом примере положительным классом будем считать увольнение.
| sex | experience | wd | salary | quit | |
|---|---|---|---|---|---|
| 0 | female | 184.5 | 39.0 | 3738 | 0 |
| 1 | female | 34.5 | 47.0 | 3079 | 0 |
| 2 | female | 79.4 | 42.5 | 2887 | 0 |
| 3 | male | 4.7 | 47.5 | 2742 | 0 |
| 4 | female | 56.3 | 64.0 | 3483 | 0 |
| 116 | male | 28.1 | 26.0 | 2651 | 0 |
| 117 | female | 19.0 | 63.0 | 3177 | 0 |
| 118 | female | 18.9 | 49.0 | 2239 | 0 |
| 119 | male | 46.6 | 4.0 | 4731 | 0 |
| 120 | female | 21.5 | 17.5 | 2163 | 0 |
- sex - пол
- experience - стаж работы в месяцах
- wd - количество отработанных смен
- salary - среднесменная заработная плата
- quit - метка 0-работает, 1 - уволился
| sex | experience | wd | salary | quit | |
|---|---|---|---|---|---|
| 98 | 1 | 93.8 | 40.5 | 6092 | 0 |
| 38 | 0 | 0.9 | 19.0 | 3734 | 0 |
| 34 | 0 | 20.6 | 23.0 | 3526 | 0 |
| 104 | 0 | 13.2 | 44.0 | 3687 | 0 |
| 115 | 0 | 18.5 | 33.5 | 3494 | 0 |
print('Labels counts in label:', np.bincount(label))
print('Labels counts in l_train:', np.bincount(l_train))
print('Labels counts in l_test:', np.bincount(l_test))
print('Labels % in label:', round(label.mean(),2))
print('Labels % in l_train:', round(l_train.mean(),2))
print('Labels % in l_test:', round(l_test.mean(),2))
Labels counts in y: [103 18] Labels counts in y_train: [61 11] Labels counts in y_test: [42 7] Labels % in y: 0.15 Labels % in y_train: 0.15 Labels % in y_test: 0.14
Как видим, процент меток класса очень близки в основном наборе и в обучающей и тестовой частях.
Для решения нашей задачи используем классификатор на основе случайного леса из sklearn.ensemble и сразу выведем метрики качества включая матрицу ошибок
from sklearn import metrics
from sklearn.metrics import plot_confusion_matrix
rfr_model.fit(d_train, l_train)
predicted = rfr_model.predict(d_test)
score = metrics.accuracy_score(l_test, predicted)
print(f'Decision Tree Classification Score = {score:.1%}\n')
print(f'Classification Report:\n {metrics.classification_report(l_test, predicted)}\n')
plot_confusion_matrix(rfr_model, d_test, l_test, cmap='Greys')
Decision Tree Classification Score = 89.8%
Classification Report:
precision recall f1-score support
0 0.93 0.95 0.94 42
1 0.67 0.57 0.62 7
accuracy 0.90 49
macro avg 0.80 0.76 0.78 49
weighted avg 0.89 0.90 0.89 49
Как видим, результат неплохой, доля правильных ответов 89.8%
features_response = d_test.columns.tolist()
feat_imp_df = pd.DataFrame({
'Importance':rfr_model.feature_importances_},
index=features_response)
feat_imp_df.sort_values('Importance', ascending=True).plot.barh()

В результате выполнения кода отображается график, который располагает признаки в наборе данных по их относительной важности, при этом показатели важности признаков нормализованы, в сумме давая 1.0.
По степени важности вперед вышли два показателя - стаж и количество отработанных смен, это говорит о том, что для сокращения текучести кадров необходимо оказывать повышенное внимание новым сотрудникам.
Комментариев нет:
Отправить комментарий