В качестве примера используем некоторые дневные показатели работы четырех розничных магазинов одежды в июле августе 2019 года.
df
| date | shop | rev | visit | item | ch | shifts | conv | lch | price | visit_per_shift | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2019-06-01 | Sh1 | 9695 | 760 | 206 | 68 | 9 | 0.089 | 3.029 | 47.063 | 84.444 |
| 1 | 2019-06-01 | Sh2 | 8921 | 248 | 166 | 39 | 5 | 0.157 | 4.256 | 53.741 | 49.600 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 366 | 2019-08-31 | Sh3 | 2632 | 221 | 69 | 29 | 4 | 0.131 | 2.379 | 38.145 | 55.250 |
| 367 | 2019-08-31 | Sh4 | 2357 | 277 | 61 | 28 | 5 | 0.101 | 2.179 | 38.639 | 55.400 |
368 rows × 11 columns
Обозначения :
- shop - индекс магазина
- rev - выручка
- visit - количество посетителей
- item - количество покупок
- ch - количество чеков
- shifts - количество смен продавцов
- conv - конверсия = количество чеков / количество посетителей
- lch - длина чека = количество покупок / количество чеков
- price - средняя цена покупки = выручка / количество покупок
- visit_per_shift - количество посетителей на смену





Эта формула представляется как сумма произведений стандартизированных значений x и y, однако мне кажется более правильным рассмотреть другой ее вариант
$$r=\frac{1}{n}\sum_{i=1}^{n}\frac{\left ( x_{i}-\bar{x}_{i} \right )\left ( y_{i}-\bar{y}_{i} \right )}{S_{x}S_{y}}$$
Слагаемые в числителе выражают взаимодействие двух переменных и определяют знак корреляции. Если между переменными существует сильная положительная взаимосвязь (увеличение одной переменной при увеличении второй), каждое слагаемое будет положительным числом : когда точка характеризуется высоким значением x и y (выше среднего), произведение будет положительным, когда точка характеризуется низким значением (ниже среднего), произведение все равно будет положительным. Аналогично, если между переменными существует сильная отрицательная связь, все слагаемые будут отрицательными числами, что в результате даст отрицательное значение корреляции.
Знаменатель просто нормирует числитель таким образом, что коэффициент корреляции оказывается легко интерпретируемым чистым (т.е. не имеющим размерности) числом в диапазоне от -1 до 1. а
Числитель выражения для коэффициента корреляции, который трудно интерпретировать из-за необычных единиц измерения, называется ковариацией. Ковариация иногда используется как самостоятельная характеристика , например , в теории финансов для описания совместного изменения курса акций на биржах. Но намного чаще используется коэффициент корреляции, оба показателя представляют, по сути, одну и ту же информацию, однако корреляция представляет ею в более удобной форме.
Некоторые положения, связанные с коэффициентом корреляции :
- коэффициент корреляции полезен только для измерения линейной связи
- большой коэффициент корреляции не является показателем причинно-следственная связь между двумя переменными
- формула коэффициента корреляции симметрична относительно x и y, т.е. корреляция x с y - это тоже самое, что корреляция y с x, т.е., какая из двух переменных будет указана первой, значение не имеет, это утверждение справедливо для корреляции, но несправедливо для регрессии.
Корреляционная матрица
| rev | visit | item | ch | shifts | conv | lch | price | visit_per_shift | |
|---|---|---|---|---|---|---|---|---|---|
| rev | 1.00 | 0.80 | 0.96 | 0.92 | 0.79 | 0.16 | 0.40 | 0.47 | 0.56 |
| visit | 0.80 | 1.00 | 0.85 | 0.90 | 0.84 | -0.29 | 0.10 | 0.14 | 0.85 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| price | 0.47 | 0.14 | 0.25 | 0.22 | 0.26 | 0.28 | 0.19 | 1.00 | -0.03 |
| visit_per_shift | 0.56 | 0.85 | 0.65 | 0.72 | 0.46 | -0.41 | -0.04 | -0.03 | 1.00 |
9 rows × 9 columns
Нагляднее будет представить ее в виде тепловой карты
sns.heatmap(df.corr(),vmin=-0.3,vmax=0.6,center=0,annot=True,fmt='.2f',
mask=~np.tri(df.corr().shape[1], k=-1, dtype=bool),
linewidth=2,cbar=False)

Уравнение регрессии
Теперь, когда мы знаем, как рассчитывается относительная
взаимосвязь между двумя переменными, мы можем разработать уравнение регрессии
для прогнозирования или предсказания желаемой переменной. Ниже приведена
формула простой линейной регрессии. «y» — это значение, которое мы пытаемся
спрогнозировать, «b» — это наклон линии регрессии, «x» — это значение нашего
независимого значения, а «a» представляет точку пересечения с осью y. Уравнение
регрессии просто описывает взаимосвязь между зависимой переменной (y) и
независимой переменной (x).
$$y=a+bx$$
Наклон Наклон «b» равен коэффициенту корреляции, умноженному на отношение двух стандартных отклонений.
Точка пересечения, или «а», представляет собой значение у (зависимой переменной), если значение х (независимая переменная) равно нулю, и поэтому иногда его просто называют «константой». Линейная регрессия пытается оценить линию, которая лучше всего соответствует данным (линия наилучшего соответствия), и уравнение этой линии приводит к уравнению регрессии. Коэффициенты уравнения регрессии находятся методом наименьших квадратов, задача которого минимизировать среднеквадратичную ошибку (mean squared error - MSE)
Подробное описание метрик качества регрессии можно посмотреть в статье "
Машинное обучение с Python в розничной торговле : метрики качества в задачах регрессии" от 20.03.22.
Регрессия является одним из методов машинного обучения, поэтому дальше мы будем рассматривать ее с этой точки зрения. Существует несколько библиотек языка Python с надежными реализациями широкого диапазона алгоритмов машинного обучения. Одна из самых известных — Scikit-Learn, пакет, предоставляющий эффективные версии множества распространенных алгоритмов, включая регрессию.
Краткий обзор основных положений, необходимых для работы с библиотекой :
Машинное обучение можно представить в виде набора моделей, реализующий определенный алгоритм
На вход модели поступают данные
Данные для МО представляют собой таблицы
Таблица - это двумерная сетка данных, в которой строки представляют отдельные элементы набора данных, а столбцы — атрибуты, связанные с каждым из этих элементов.
Каждая строка данных относится к одному из измерений моделируемых объектов и количество строк равно количеству объектов в наборе (например в нашем примере - это дата или день, в котором мы рассматриваем определенный процес, в данном случае это торговый день).
Будем называть столбцы матрицы выборками (samples), а количество строк полагать равным n_samples Каждый столбец данных относится к конкретному количественному показателю, описывающему данную выборку.
Мы будем называть столбцы матрицы признаками (features), а количество столбцов полагать равным n_features.
Из устройства таблицы очевидно, что информацию можно рассматривать как двумерный числовой массив или матрицу, которую мы будем называть матрицей признаков (features matrix).
По традиции матрицу признаков часто хранят в переменной X.
Предполагается, что матрица признаков — двумерная, с формой [n_samples, n_features], и хранят ее чаще всего в массиве NumPy или объекте DataFrame библиотеки Pandas.
1.Выбор класса модели. Каждый класс модели в библиотеке Scikit-Learn представлен соответствующим классом языка Python. Так, например, для расчета модели простой линейной регрессии можно импортировать класс линейной регрессии:
from sklearn.linear_model import LinearRegression
2.Выбор гиперпараметров модели. Подчеркнем важный момент: класс модели — не то же самое, что экземпляр модели. После выбора класса модели у нас все еще остаются некоторые возможности для выбора. В зависимости от нашего класса модели может понадобиться ответить на один или несколько следующих вопросов.
- Хотим ли мы выполнить подбор сдвига прямой (то есть точки пересечения с осью координат)?
- Хотим ли мы нормализовать модель?
- Хотим ли мы сделать модель более гибкой, выполнив предварительную обработку признаков?
- Какая степень регуляризации должна быть у нашей модели?
- Сколько компонент модели мы хотели бы использовать?
Это примеры тех важных решений, которые нам придется принять после выбора класса модели. Результаты этих решений часто называют гиперпараметрами, то есть параметрами, задаваемыми до обучения модели на данных. Выбор гиперпараметров в библиотеке Scikit-Learn осуществляется путем передачи значений при создании экземпляра модели.
Создадим экземпляр класса LinearRegression и укажем с помощью гиперпараметра fit_intercept, что нам бы хотелось выполнить подбор точки пересечения с осью координат
regr = LinearRegression(fit_intercept=True)
3. Формирование из данных матриц признаков и целевого вектора. Наша целевая переменная y уже имеет нужный вид (массив длиной n_samples), но нам придется проделать небольшие манипуляции с данными x, чтобы сделать из них матрицу размера [n_samples, n_features]. В данном случае манипуляции сводятся просто к изменению формы одномерного массива:
X.shape
(92, 1)
#Обучение модели на наших данных. Сделать это можно с помощью метода fit() модели:
regr.fit(X, y)
Команда fit() вызывает выполнение «под капотом» множества вычислений, в зависимости от модели, и сохранение результатов этих вычислений в атрибутах модели, доступных для просмотра пользователем. В библиотеке Scikit-Learn по традиции все параметры модели, полученные в процессе выполнения команды fit(), содержат в конце названия знак подчеркивания. Например, в данной линейной модели:
[-0.00023762] 0.10396857101918738
Эти два параметра представляют собой угловой коэффициент и точку пересечения
с осью координат для простой линейной аппроксимации наших данных.
Для получения предсказанных моделью значений используется метод predict
y_lin_fit = regr.predict(X)
Визуализируем наш резульат
sns.scatterplot(x=X[:,0], y=y)
sns.lineplot(x=X[:,0], y=y_lin_fit)
plt.xlabel('visit_per_shift')
plt.ylabel('conv')
plt.title('simple linear regression cov ~ visit_per_shift')

Рассчитываем метрики качества модели
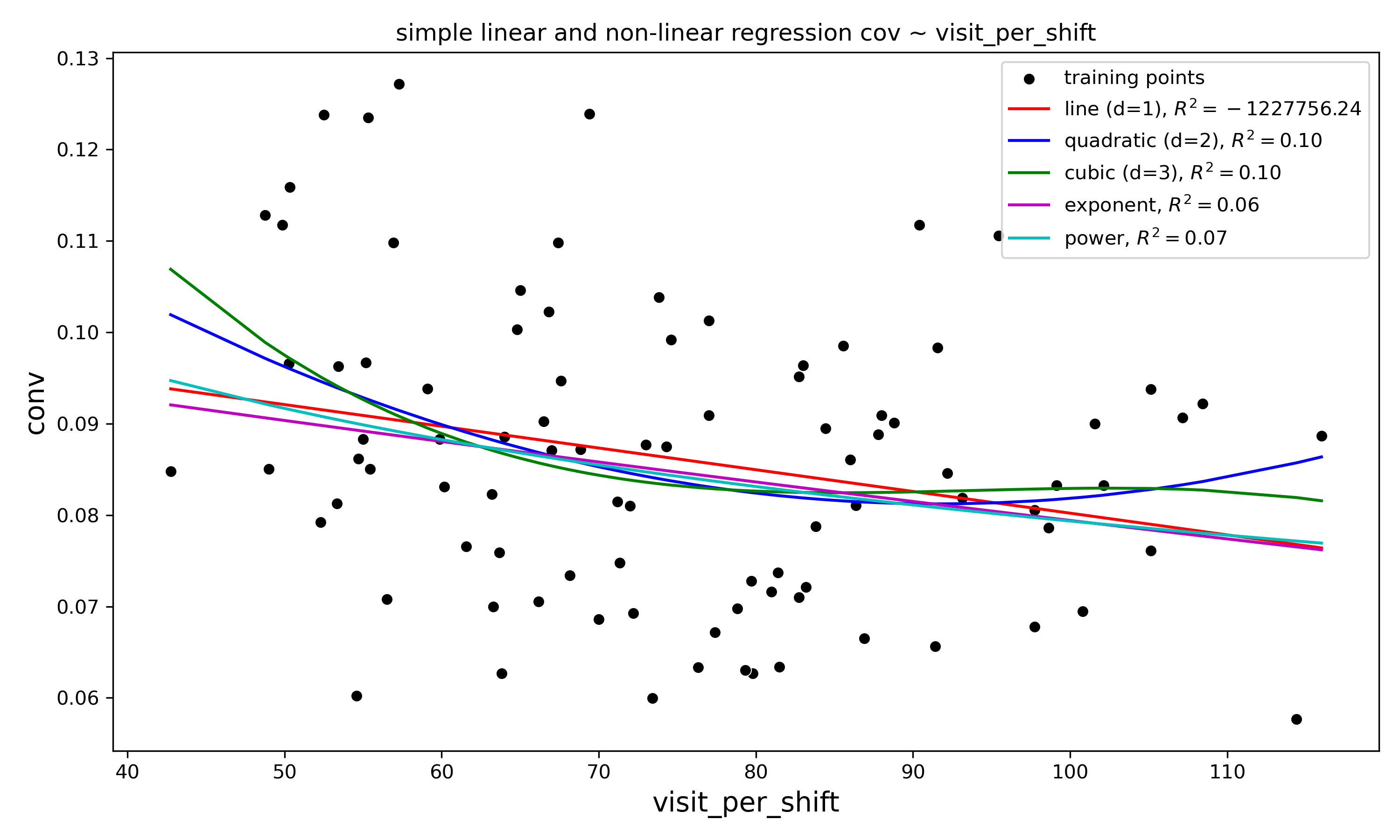
Decision Linear Regression Metrics: R^2 Score = 0.065 Mean Absolute Percentage Error = 15.15 Mean Absolute Error = 0.01 Mean Squared Error = 0.00 Root Mean Squared Error = 0.02
Глядя на график рассеяния можно предположить, что связь между нашими переменными нелинейная. В этом случае один из подходов предусматривает использованиеполиномиальной регрессионной модели путем добавления полиномиальных членов
$$y=a+b_{1}x+b_{2}x^2+...+b_{d}x^d$$
Здесь d обозначает степень полинома. Для преобразования нашей модели используемкласс преобразователя PolynomialFeatures для добавления квадратичного (d=2) и кубичного (d=3) члена.
from sklearn.preprocessing import PolynomialFeatures
X_quad = PolynomialFeatures(degree=2).fit_transform(X)
regr = regr.fit(X_quad, y)
y_quad_fit = regr.predict(X_quad)
# Рассчитываем метрики качества
quad_mae = metrics.mean_absolute_error(y, y_quad_fit)
quad_mse = metrics.mean_squared_error(y, y_quad_fit)
quad_mape = MAPE(y, y_quad_fit)
quad_rmse = math.sqrt(quad_mse)
quad_r2 = metrics.r2_score(y, y_quad_fit)
# Выводим метрики
print('Decision Quadratic Regression Metrics:')
print(f'R^2 Score = {quad_r2:.3f}')
print(f'Mean Absolute Percentage Error = {quad_mape:.2f}')
print(f'Mean Absolute Error = {quad_mae:.2f}')
print(f'Mean Squared Error = {quad_mse:.2f}')
print(f'Root Mean Squared Error = {quad_rmse:.2f}')Decision Quadratic Regression Metrics: R^2 Score = 0.096 Mean Absolute Percentage Error = 14.84 Mean Absolute Error = 0.01 Mean Squared Error = 0.00 Root Mean Squared Error = 0.02X_cub = PolynomialFeatures(degree=3).fit_transform(X) regr = regr.fit(X_cub, y) y_cub_fit = regr.predict(X_cub) # Рассчитываем метрики качества cub_mae = metrics.mean_absolute_error(y, y_cub_fit) cub_mse = metrics.mean_squared_error(y, y_cub_fit) cub_mape = MAPE(y, y_cub_fit) cub_rmse = math.sqrt(cub_mse) cub_r2 = metrics.r2_score(y, y_cub_fit) # Выводим метрики print('Decision Cubic Regression Metrics:') print(f'R^2 Score = {cub_r2:.3f}') print(f'Mean Absolute Percentage Error = {cub_mape:.2f}') print(f'Mean Absolute Error = {cub_mae:.2f}') print(f'Mean Squared Error = {cub_mse:.2f}') print(f'Root Mean Squared Error = {cub_rmse:.2f}')Не ограничимся этим, и используем експоненциальную и степенную модели#Экспоненциальная модель y=ab^xy_log=np.log(y) regr = regr.fit(X, y_log) y_exp_fit = regr.predict(X) # Рассчитываем метрики качества exp_mae = metrics.mean_absolute_error(y, np.exp(y_exp_fit)) exp_mse = metrics.mean_squared_error(y, np.exp(y_exp_fit)) exp_mape = MAPE(y, np.exp(y_exp_fit)) exp_rmse = math.sqrt(exp_mse) exp_r2 = metrics.r2_score(y, np.exp(y_exp_fit)) # Выводим метрики print('Decision Exp Regression Metrics:') print(f'R^2 Score = {exp_r2:.3f}') print(f'Mean Absolute Percentage Error = {exp_mape:.2f}') print(f'Mean Absolute Error = {exp_mae:.2f}') print(f'Mean Squared Error = {exp_mse:.2f}') print(f'Root Mean Squared Error = {exp_rmse:.2f}')#Степенная модель y=ax^by_log=np.log(y) X_log=np.log(X) regr = regr.fit(X_log, y_log) y_pow_fit = regr.predict(X_log) # Рассчитываем метрики качества pow_mae = metrics.mean_absolute_error(y, np.exp(y_pow_fit)) pow_mse = metrics.mean_squared_error(y, np.exp(y_pow_fit)) pow_mape = MAPE(y, np.exp(y_pow_fit)) pow_rmse = math.sqrt(pow_mse) pow_r2 = metrics.r2_score(y, np.exp(y_pow_fit)) # Выводим метрики print('Decision Power Regression Metrics:') print(f'R^2 Score = {pow_r2:.3f}') print(f'Mean Absolute Percentage Error = {pow_mape:.2f}') print(f'Mean Absolute Error = {pow_mae:.2f}') print(f'Mean Squared Error = {pow_mse:.2f}') print(f'Root Mean Squared Error = {pow_rmse:.2f}')Decision Power Regression Metrics:R^2 Score = 0.070 Mean Absolute Percentage Error = 14.88 Mean Absolute Error = 0.01 Mean Squared Error = 0.00 Root Mean Squared Error = 0.02Чтобы лучше представить, что у нас получилось, выведем графикиplt.figure(figsize=(10,6)) sns.scatterplot(x=X[:,0], y=y,label='training points', color='k') sns.lineplot(x=X[:,0], y=y_lin_fit,label='line (d=1),$R^2={:.2f}$'.format(lin_r2),color = 'r') sns.lineplot(x=X[:,0], y=y_quad_fit,label='quadratic (d=2),$R^2={:.2f}$'.format(quad_r2),color = 'b') sns.lineplot(x=X[:,0], y=y_cub_fit,label='cubic (d=3),$R^2={:.2f}$'.format(cub_r2),color = 'g') sns.lineplot(x=X[:,0], y=np.exp(y_exp_fit),label='exponent,$R^2={:.2f}$'.format(exp_r2),color='m') sns.lineplot(x=X[:,0], y=np.exp(y_pow_fit),label='power,$R^2={:.2f}$'.format(pow_r2),color='c') plt.xlabel("visit_per_shift", fontsize=14) plt.ylabel("conv", fontsize=14) plt.legend(loc='upper right') plt.xlabel('visit_per_shift') plt.ylabel('conv') plt.title('simple linear and non-linear regression cov ~ visit_per_shift')
Также выведем остатки моделейmodel_name=['line (a+b*x)','quadratic (a+b1*x+b2*x^2)','cubic (a+b1*x+b2*x^2+b3*x^3)','exponent (a*b^x)','power (a*x^b)',''] fig, axs = plt.subplots(3, 2, figsize=(12, 10), sharey=True) plt.subplots_adjust(hspace=0.5) axs[0,0].scatter(X[:,0], y - y_lin_fit,c='steelblue', marker='o', edgecolor='white',label='line') axs[0,1].scatter(X[:,0], y - y_quad_fit,c='g', marker='s', edgecolor='white',label='line') axs[1,0].scatter(X[:,0], y - y_cub_fit,c='r', marker='h', edgecolor='white',label='line') axs[1,1].scatter(X[:,0], y - np.exp(y_exp_fit),c='m', marker='H', edgecolor='white',label='line') axs[2,0].scatter(X[:,0], y - np.exp(y_pow_fit),c='b', marker='8', edgecolor='white',label='line') fig.delaxes(axs[2,1]) for i,ax in enumerate(axs.flat): ax.set(xlabel='visit_per_shift', ylabel='residual') ax.axhline (y = 0, color = 'b') ax.set_title("model "+model_name[i])

| date | Sh1_visit | Sh2_visit | Sh3_visit | Sh4_visit | Sh1_rev | Sh2_rev | Sh3_rev | Sh4_rev | total_visit | total_rev | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2019-06-01 | 760 | 248 | 203 | 354 | 9695 | 8921 | 2820 | 2582 | 1565 | 24018 |
| 1 | 2019-06-02 | 797 | 210 | 243 | 423 | 7864 | 3825 | 2741 | 4077 | 1673 | 18507 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 90 | 2019-08-30 | 374 | 111 | 185 | 240 | 4381 | 3739 | 713 | 1257 | 910 | 10090 |
| 91 | 2019-08-31 | 683 | 224 | 221 | 277 | 12049 | 12147 | 2632 | 2357 | 1405 | 29185 |
92 rows × 11 columns
Перед нами дневные показатели работы четырех розничных магазинов : дневная проходимость и дневная выручка, также выведены суммарные показатели. Из этого набора данных отберем только проходимость каждого магазина и итоговую выручку.
df1
| Sh1_visit | Sh2_visit | Sh3_visit | Sh4_visit | total_rev | |
|---|---|---|---|---|---|
| 0 | 760 | 248 | 203 | 354 | 24018 |
| 1 | 797 | 210 | 243 | 423 | 18507 |
| ... | ... | ... | ... | ... | ... |
| 90 | 374 | 111 | 185 | 240 | 10090 |
| 91 | 683 | 224 | 221 | 277 | 29185 |
92 rows × 5 columns
Выведем диаграммы рассеяния
plt.subplots_adjust(wspace=0.5)
ax[0].scatter(df1.Sh1_visit,df.total_rev,color="g")
ax[1].scatter(df1.Sh2_visit,df.total_rev,color="r")
ax[2].scatter(df1.Sh3_visit,df.total_rev,color="b")
ax[3].scatter(df1.Sh4_visit,df.total_rev,color="m")
ax[0].set_xlabel("Sh1 visit")
ax[1].set_xlabel("Sh2 visit")
ax[2].set_xlabel("Sh3 visit")
ax[3].set_xlabel("Sh4 visit")
ax[0].set_ylabel("total rev");

И сделаем модель, которая по проходимости будет нам прогнозировать итоговую
выручку по показателям посетителей
y= df1['total_rev'].values
regr = LinearRegression(fit_intercept=False)
regr.fit(X, y)
y_pred = regr.predict(X)
# Рассчитываем метрики качества
mae = metrics.mean_absolute_error(y, y_pred)
mse = metrics.mean_squared_error(y, y_pred)
mape = MAPE(y, y_pred)
rmse = math.sqrt(lin_mse)
r2 = metrics.r2_score(y, y_pred)
# Выводим метрики
print(f'R^2 Score = {r2:.3f}')
print(f'Mean Absolute Percentage Error = {mape:.2f}')
print(f'Mean Absolute Error = {mae:.2f}')
print(f'Mean Squared Error = {mse:.2f}')
print(f'Root Mean Squared Error = {rmse:.2f}')
Decision Linear Regression Metrics: R^2 Score = 0.856 Mean Absolute Percentage Error = 13.81 Mean Absolute Error = 1722.79 Mean Squared Error = 4997263.18 Root Mean Squared Error = 17.67
Выведем графики остатков модели в координатах объясняющих переменных
fig, axs = plt.subplots(2, 2, figsize=(12, 10), sharey=True)
axs[0,0].scatter(X[:,0], y - y_pred,c='steelblue',
marker='o', edgecolor='white',label='line')
axs[0,1].scatter(X[:,1], y - y_pred,c='g',
marker='s', edgecolor='white',label='line')
axs[1,0].scatter(X[:,2], y - y_pred,c='r',
marker='h', edgecolor='white',label='line')
axs[1,1].scatter(X[:,3], y - y_pred,c='m',
marker='H', edgecolor='white',label='line')
for i,ax in enumerate(axs.flat):
ax.set(xlabel=col[i], ylabel='residual')
ax.axhline (y = 0, color = 'b')

Комментариев нет:
Отправить комментарий